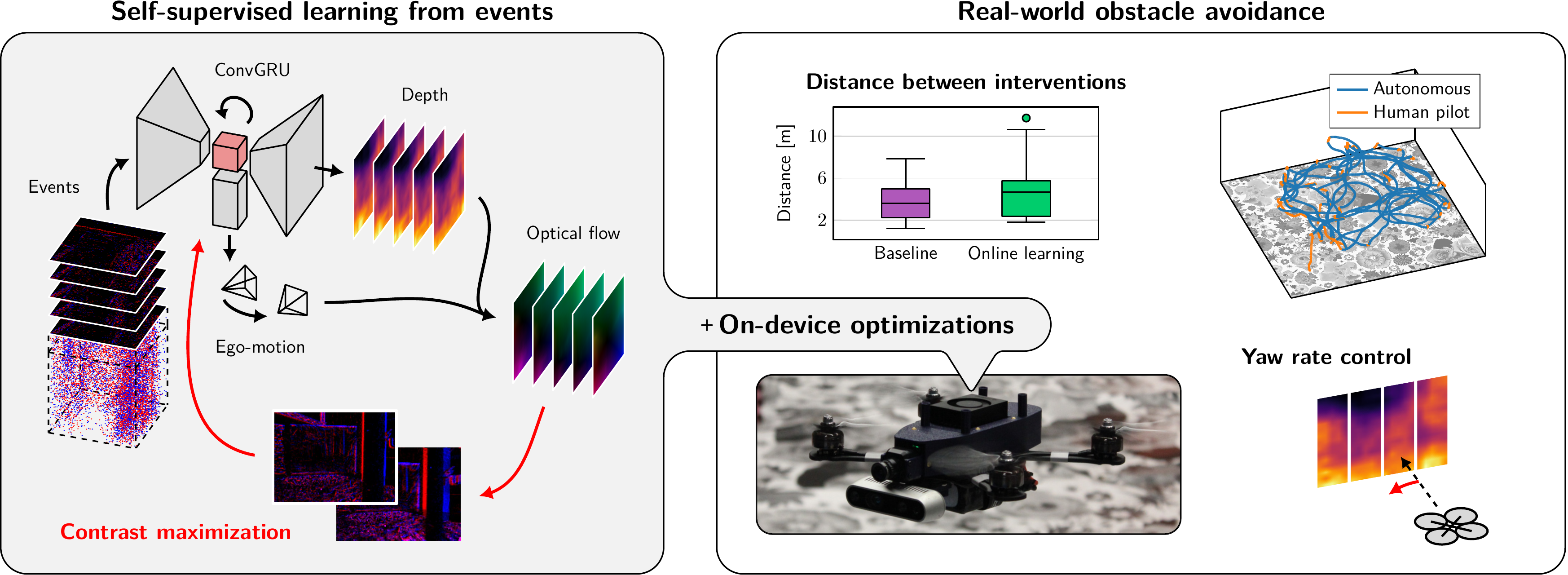
Our work on online, on-board learning of depth from events has been accepted at CVPR 2025.
Event cameras provide low-latency perception for only milliwatts of power. This makes them highly suitable for resource-restricted, agile robots such as small flying drones. Self-supervised learning based on contrast maximization holds great potential for event-based robot vision, as it foregoes the need for high-frequency ground truth and allows for online learning in the robot’s operational environment. However, online, on-board learning raises the major challenge of achieving sufficient computational efficiency for real-time learning, while maintaining competitive visual perception performance. In this work, we improve the time and memory efficiency of the contrast maximization pipeline, making on-device learning of low-latency monocular depth possible. We demonstrate that online learning on board a small drone yields more accurate depth estimates and more successful obstacle avoidance behavior compared to only pre-training. Benchmarking experiments show that the proposed pipeline is not only efficient, but also achieves state-of-the-art depth estimation performance among self-supervised approaches. Our work taps into the unused potential of online, on-device robot learning, promising smaller reality gaps and better performance.
Relevant links
Paper
Code: drone, training, CUDA extension